This is an old revision of the document!
| Summary |
| Reconstructing large models from images is a significant challenge for computer graphics, computer vision, and related fields. In this project, we investigate an approach for simplifying the reconstruction process by mathematically eliminating external camera parameters. This results in less parameters to estimate and in an overall significantly more robust and accurate reconstruction. Unlike self-calibration, omitting pose parameters from the acquisition process implies no external calibration data must be computed or provided. We reformulate the problem in such a manner as to be able to identify invariants, eliminate superfluous parameters, and measure the performance of our formulation under various conditions. We compare a two-step camera orientation-free method, where the majority of the points are reconstructed using a linear equation set, and a camera position-and-orientation free method, using a degree-two equation set. Aside from freely taking pictures and moving an uncalibrated digital projector, scene acquisition and scene point reconstruction is automatic and requires pictures from only a few viewpoints. We demonstrate how the combination of these benefits has enabled us to acquire several large and detailed models. |
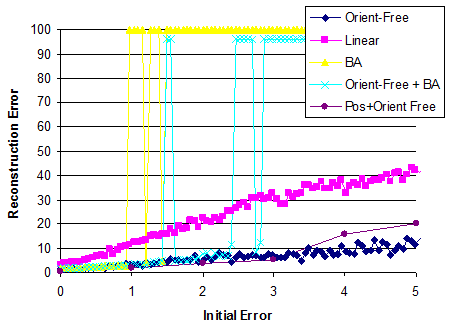
Comparison of all Methods. Using an experiment with known ground truth, we compare pose-included methods to our orientation-free and pose-free methods. In all cases our method exhibits significantly higher robustness and accuracy. |   
  
Orientation-Free Reconstructions. We show several reconstructions of the giraffe dataset using our orientation-free method (bottom row) and using standard pose-included bundle adjustment (top row). The error of the different reconstructions is shown by drawing lines between the reconstructed points and the highest quality reconstruction (e.g., ground truth). (top-left) Example input image from giraffe sequence. (left-bottom) High-quality reconstruction using our method. (top-middle) Medium-quality solution using standard BA. (bottom-middle) Medium-quality solution using our method. (top-right) Low-quality solution using standard BA. (bottom-right) Low-quality solution using our method. |
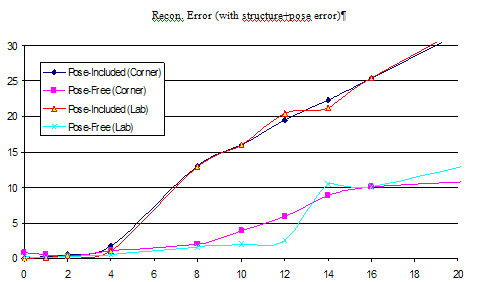
Comparison to Pose-Included for Large Datasets. We show the reconstruction error using our two largest datasets for both our pose-free formulation and for pose-included formulation. Equal amounts of structure and pose error are introduced to create this graph. Values are expressed as a percentage of the 10-meter model diagonal of the models. |   
  
Scene Reconstruction. The top row shows reconstructed scene points and the bottom row contains texture-mapped triangulations of the same scene points., both using our completely pose-free formulation. The scene points for both clusters were solved for in a single reconstruction. (left column) Reconstruction of cluster A. (middle column) Reconstruction of cluster B. (right column) Both clusters rendered together. |
 
  | 
Global Multi-viewpoint Model. Our method enables easy, robust, and accurate capturing of large scenes assembled from multiple acquisitions (left) in a single global reconstruction (top). Our approach produces texture-mapped geometric models and captures dense and high-detailed scene information. |
 Research supported by NSF MSPA-MCS Grant No. 0434398 Research supported by NSF MSPA-MCS Grant No. 0434398 |


















